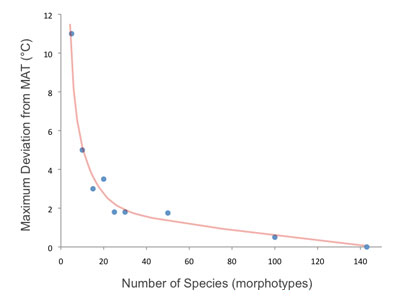
4. Sampling and scoring ‘errors’To maximize precision in the face of natural heterogeneity CLAMP uses several collection and scoring strategies. Collection for calibration is over a limited area. This is in order to minimize the variation in free-air climate at a sampling site. Typically this would be within 0.5 km of a central point and at the same altitude. Gregory-Wodzicki (2000) pointed out the wisdom of adopting this strategy in contrast to less constrained data derived from floral manuals that relate to taxa distributed over large, often undefined areas (e.g. Wilf et al., 1998; 1999). By restricting CLAMP sampling to small areas the climate can be better defined and the range of variation in leaf characters is reduced. This in turn contributes to greater precision (Wolfe and Uemura, 1999). Taphonomic work has repeatedly shown (Burnham et al., 2001; Ferguson, 1985; Spicer, 1981; Spicer, 1989) that leaf assemblages tend to reflect local, rather than regional, vegetation and thus CLAMP sampling is designed to be analogous to the natural sampling that results in a fossil assemblage. Nevertheless the scoring process relies on collecting the full range of leaf morphologies displayed within a species at a site and some morphologies may be overlooked. Once collected the leaf sample may be miss-scored, but experiments with novice scorers, even those speaking different languages, have shown that, following improvements in scoring instructions, this is now less of a problem than perhaps it once was (Spicer and Yang, 2010). Undoubtedly having numerous taxa scored for numerous character states minimizes the effect of miss-scoring for a given character or species. However, no amount of inbuilt robustness can overcome problems that are introduced if the CLAMP sampling or scoring protocols are not adhered to. Attempts to change the scoring regime, particularly without recalibrating CLAMP, only degrades the outcome (see Peppe et al., 2010 and compare with Spicer and Yang, 2010). Some have argued for continuous, rather than categorical, scores particularly for such characters as leaf size. Attractive as this is in terms of limiting scoring uncertainty it unfortunately captures all the natural variation present, much of which may be ‘noise’ in the sense that small differences in large leaves are likely to have less significance than small differences in small leaves. Logarithmic transform can overcome this but so does categorical scoring. This has been clearly demonstrated in palaeoecological studies (Spicer and Hill, 1979). Computer-based automated scoring is undoubtedly attractive, but it is not yet available in a useful form. LMA and CLAMP both rely on measurements of populations of species (morphotypes) in a given area. Empirical studies have shown that for CLAMP no fewer than 20 species should be scored for each site (Povey et al., 1994). For LMA Steart et al. (2010) suggest no fewer than 15 taxa should be used.
|
||||||
 |
 |
Uncertainties (in CLAMP and other climate proxies) |
Overview |
Taphonomic |
Climatic |
Environmental |
Sampling & Scoring |
CLAMP Stats. |