
CLAMP 'Classic' Spreadsheets for Calculating Climate Results
Overview
The CLAMP results spreadsheets provide an automated set of climate predictions derived from CANOCO solution files. Biplot scores for the unknown fossil sites are pasted from the solution files into the spreadsheet which automatically computes the positions along each of the climate parameter vectors for each site, both modern and fossil. These computations are carried out in four dimensional space. The biplot scores for the first four axes are used.
The climate parameter vector scores have been previously plotted against the observed climate parameter values to obtain a 2nd order polynomial regression equation to convert the climate parameter vector scores for the fossil sites into climate parameter predictions.
The speadsheets utilise the Genfit polynomial regression facility that is part of xlSTAT, an Add-In for Excel distributed by Kovach Computing. This equation is built in to the spreadsheets and is used to calculate the climate predictions.
The spreadsheets come in several forms, each appropriate to a particular CLAMP dataset. Any modification of the data set requires modification of the speadsheets, but if the standard data sets are used, apart from adding up to 20 fossil sites as unknowns, then no alteration of the spreadsheets is required.
Why use the spreadsheets?
CANOCO does not generate climate parameter predictions by itself. It only defines the co-ordinates of the fossil sites in physiognomic space together with the directions of climate parameter vectors (Mean Annual Temperature, Mean Monthly Growing Season Precipitation etc.) in that physiognomic space. To obtain climatic data for a given fossil site its position, as defined by two or more Axis scores, needs to be projected on to a given climate parameter vector. This climate parameter vector is calibrated by the projected positions of the modern vegetation sites growing under known climatic conditions. The purpose of the spreadsheets is to do the calculations associated with the vector calibration and determine the projected distance along the calibrated vector of the fossil site. Once this distance is computed the calibration is used by the spreadsheets to determine the palaeoclimate of the fossil site. In the spreadsheets the position along the vectors is calculated in four dimensional space.
The following diagram illustrates the regression curve for the plot of Mean Annual Temperature (MAT) vector score against the observed MAT for the modern vegetation sites in two dimensional space.
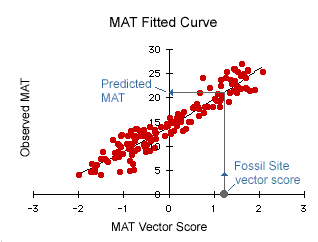
In this case from a fossil site vector score of 1.2 we get a predicted MAT for the palaeoclimate of the fossil assemblage of 21°C. Graphs of all the other climate parameter regressions are given in the results spreadsheets below.
The climate parameters predicted by these spreadsheets are:
Mean Annual Temperature (MAT) (°C)
Warm Month Mean Temperature (WMMT) (°C)
Cold Month Mean temperature (CMMT) (°C)
Length of the Growing Season (LGS) (months)
Growing Season Precipitation (GSP) (mm x 10)
Mean Monthly Growing Season Precipitation (MMGSP) (mm x 10)
Precipitation during the 3 Consecutive Wettest Months (3WET) (mm x 10)
Precipitation during the 3 Consecutive Driest Months (3DRY) (mm x 10)
Relative Humidity (RH) (%)
Specific Humidity (SH) (g/kg)
Enthalpy (ENTHAL) (kJ/kg)
Using the Spreadsheets
Below is a diagram of a typical results spreadsheet layout.

Normally the only areas of direct interest are those coloured light blue and red. The light blue area is where you paste in you fossil site biplot scores from the CANOCO solution file. As you do this the spreadsheets automatically calculate the position of your fossil sites in physiognomic space and calculate the climate predictions. These are displayed in the area coloured red, together with the standard deviation of the residuals about the regression lines (pink area) as a measure of the statistical uncertainty associated with the results. These regression statistics alter with changes to the modern data sets or a different combination of climate parameters. It is not recommended that you alter either. If you do so you will generate erroneous results unless you reconfigure the entire sreadsheets with new regression equations.
Download the 144 site results Excel 5.0/95 spreadsheet Res3brcAZ.xls(1.1Mb)Download the 173 site results Excel 5.0/95 spreadsheet Res3arcAZ.xls(1.2Mb)Download the 189 site results Excel 2004/97 spreadsheet Res3Asia1.xls(1.5Mb)
